Ongoing Work
- The Wealth and Mobility (WAM) Study
with Pablo Mitnik, Joe LaBriola, Asher Dvir-Djerassi, et al.
More informationShow Abstract
Through a collaborative project with the Internal Revenue Service Statistics of Income unit (IRS-SOI), this project will gather data on the wealth holdings of all U.S. households to support investigations of U.S. wealth inequality and intergenerational wealth transmission.Hide Abstract
Published Work
- Beyond the Diagonal Reference Model: Critiques & New Directions in the Analysis of Mobility Effects
Sociological Methods and Research (2025), with Ethan Fosse
Download, Appendix, Replication FileShow Abstract
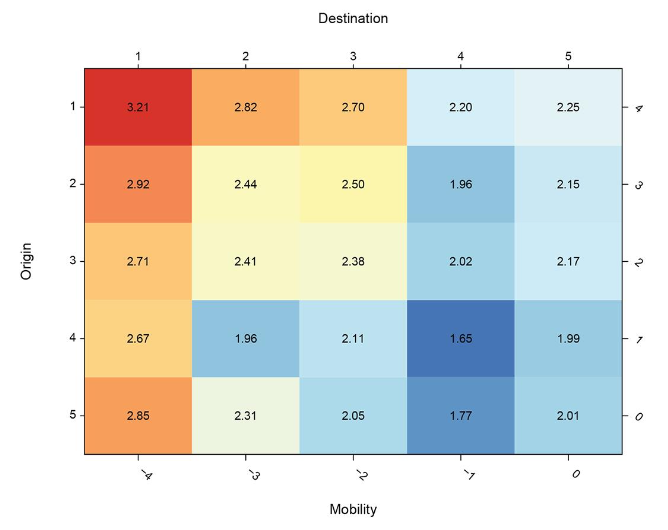
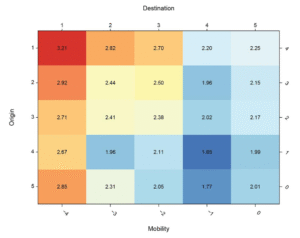 Over the past decade there has been a striking increase in the number of quantitative studies examining the effects of social (i.e., socioeconomic) mobility, with almost all recent results in sociology and demography based on the Diagonal Reference Model (DRM). This paper makes four main contributions to this rapidly expanding literature. First, we show that under plausible values of mobility effects, the DRM will, in general, implicitly force the underlying mobility linear effect to zero. In addition, we show both mathematically and through simulations that the mobility effects estimated by the DRM are sensitive to the size and sign of the origin and destination linear effects, often in ways that are unlikely to be intuitive to applied researchers. This finding clarifies why, contrary to expectations, applied researchers have generally found weak or no evidence of mobility effects on a wide range of outcomes. Second, we generalize the identification problem of conventional mobility effect models by showing that the DRM and related methods can be viewed as special cases of a bounding analysis, where identification is achieved by invoking extremely strong assumptions (resulting in very tight bounds). Finally, and importantly, we present a new framework for the analysis of mobility tables based on the identification and estimation of joint parameter sets, introducing what we call the Structural and Dynamic Inequality (SDI) model. We show that this model is fully identified, relies on much weaker assumptions than conventional models of mobility effects, and can be treated both as a descriptive model and, if additional assumptions are invoked, as a causal model. We conclude with an agenda for further research on the consequences of socioeconomic mobility.
Over the past decade there has been a striking increase in the number of quantitative studies examining the effects of social (i.e., socioeconomic) mobility, with almost all recent results in sociology and demography based on the Diagonal Reference Model (DRM). This paper makes four main contributions to this rapidly expanding literature. First, we show that under plausible values of mobility effects, the DRM will, in general, implicitly force the underlying mobility linear effect to zero. In addition, we show both mathematically and through simulations that the mobility effects estimated by the DRM are sensitive to the size and sign of the origin and destination linear effects, often in ways that are unlikely to be intuitive to applied researchers. This finding clarifies why, contrary to expectations, applied researchers have generally found weak or no evidence of mobility effects on a wide range of outcomes. Second, we generalize the identification problem of conventional mobility effect models by showing that the DRM and related methods can be viewed as special cases of a bounding analysis, where identification is achieved by invoking extremely strong assumptions (resulting in very tight bounds). Finally, and importantly, we present a new framework for the analysis of mobility tables based on the identification and estimation of joint parameter sets, introducing what we call the Structural and Dynamic Inequality (SDI) model. We show that this model is fully identified, relies on much weaker assumptions than conventional models of mobility effects, and can be treated both as a descriptive model and, if additional assumptions are invoked, as a causal model. We conclude with an agenda for further research on the consequences of socioeconomic mobility. Hide Abstract
- Methodological Frontiers in Intergenerational Mobility Research
Sociological Methods and Research (2025), with Yoosoon Chang, Steven Durlauf, and Xi Song
Download, Table of ContentsShow Abstract
This special issue of Sociological Methods & Research presents a collection of papers that develop a range of new statistical approaches and empirical insights on intergenerational mobility. The papers in the special issue involve four broad themes: the development of new statistics to characterize mobility, the exploration of methods to establish causal explanations, the enrichment of statistical models to better characterize heterogeneity in mobility across families, and the development and application of ways to employ machine learning tools to enrich mobility analysis. These papers demonstrate the excitement of the methodological frontier in mobility research.Hide Abstract
- PSID-SHELF: The Panel Study of Income Dynamics “Social, Health, and Economic Longitudinal File”
OpenICPSR (2025), with Davis Daumler and Esther Friedman
Data Access, User GuideShow Abstract
The Panel Study of Income Dynamics–Social, Health, and Economic Longitudinal File (PSID-SHELF) provides an easy-to-use and harmonized longitudinal file for the Panel Study of Income Dynamics (PSID), the longest-running nationally representative household panel survey in the world.Hide Abstract
- The Future Strikes Back. Using Future Treatments to Assess Hidden Bias
Sociological Methods & Research (2022), with Felix Elwert
Download, Appendix, Replication PackageShow Abstract
Conventional advice discourages controlling for post-outcome variables in regression analysis. By contrast, we show that controlling for commonly available post-outcome (i.e. future) values of the treatment variable can help detect, reduce, and even remove omitted variable bias (unobserved confounding). The premise is that the same unobserved confounder that affects treatment also affects the future value of the treatment. Future treatments thus proxy for the unmeasured confounder, and researchers can exploit these proxy measures productively. We establish several new results: Regarding a commonly assumed data-generating process involving future treatments, we (1) introduce a simple new approach and show that it strictly reduces bias; (2) elaborate on existing approaches and show that they can increase bias; (3) assess the relative merits of alternative approaches; (4) analyze true state dependence and selection as key challenges. (5) Importantly, we also introduce a new non-parametric test that uses future treatments to detect hidden bias even when future-treatment estimation fails to reduce bias. We illustrate these results empirically with an analysis of the effect of parental income on children’s educational attainment.Hide Abstract
- Multiple Imputation with Massive Data
Journal of Survey Statistics and Methodology (2021), with Yajuan Si and others
DownloadShow Abstract
Multiple imputation (MI) is a popular and well-established method for handling missing data in multivariate data sets, but its practicality for use in massive and complex data sets has been questioned. One such data set is the Panel Study of Income Dynamics (PSID), a longstanding and extensive survey of household income and wealth in the United States. Missing data for this survey are currently handled using traditional hot deck methods because of the simple implementation; however, the univariate hot deck results in large random wealth fluctuations. MI is effective but faced with operational challenges. We use a sequential regression/chained-equation approach, using the software IVEware, to multiply impute cross-sectional wealth data in the 2013 PSID, and com- pare analyses of the resulting imputed data with those from the current hot deck approach. Practical difficulties, such as non-normally distributed variables, skip patterns, categorical variables with many levels, and multicollinearity, are described together with our approaches to over- coming them. We evaluate the imputation quality and validity with internal diagnostics and external benchmarking data. MI produces improvements over the existing hot deck approach by helping preserve correlation structures, such as the associations between PSID wealth components and the relationships between the household net worth and sociodemographic factors, and facilitates completed data analyses with general purposes. MI incorporates highly predictive covariates into imputation models and increases efficiency. We recommend the practical implementation of MI and expect greater gains when the fraction of missing information is large.Hide Abstract
- The Longitudinal Revolution. Sociological Research at the 50-Year Milestone of the Panel Study of Income Dynamics
Annual Review of Sociology (2020), with Paula Fomby and Noura Insolera
DownloadShow Abstract
 The US Panel Study of Income Dynamics (PSID) celebrated its 50th anniversary in 2018. Initially designed to assess the nation’s progress in com- batting poverty, PSID’s scope broadened quickly to a variety of topics and fields of inquiry. To date, sociologists are the second-most frequent users of PSID data after economists. Here, we describe the ways in which PSID’s history reflects shifts in social science scholarship and funding priorities over half a century; take stock of the most important sociological breakthroughs it facilitated, in particular those relying on the longitudinal structure of the data; and critically assess the unique advantages and limitations of PSID and surveys like it for today’s sociological scholarship.
The US Panel Study of Income Dynamics (PSID) celebrated its 50th anniversary in 2018. Initially designed to assess the nation’s progress in com- batting poverty, PSID’s scope broadened quickly to a variety of topics and fields of inquiry. To date, sociologists are the second-most frequent users of PSID data after economists. Here, we describe the ways in which PSID’s history reflects shifts in social science scholarship and funding priorities over half a century; take stock of the most important sociological breakthroughs it facilitated, in particular those relying on the longitudinal structure of the data; and critically assess the unique advantages and limitations of PSID and surveys like it for today’s sociological scholarship. Hide Abstract
- Linking Survey and Historical Census Data to Study Multigenerational Mobility
Technical Reports for PSID and HRS (2020), with John R. Warren, Jonas Helgertz, and Dafeng Xu
Download PSID, Download HRSShow Abstract
The project is part of a larger effort to conduct parallel linkages to the 1940 Census for respondents to the PSID, the Health and Retirement Study (HRS), the Wisconsin Longitudinal Study (WLS), the National Social Life, Health, and Aging Project (NSHAP), and the National Health and Aging Trends Study (NHATS). Each study contains sample members who were alive at the time of the 1940 federal census and were thus enumerated (along with their families and household members). These five ongoing longitudinal studies are central components of America’s data infrastructure for interdisciplinary research on aging and the life course; physical and mental health, disability, and well-being; later-life work, economic well-being, and retirement; end-of-life issues, and many other topics. Adding information about sample members from the 1940 Census expands the utility of all five projects and enables important research on the effects of early life social, economic, environmental, contextual, and other factors on subsequent life outcomes.Hide Abstract
- Determinants of Wealth Fluctuation
Methods, Data, Analyses (2017), with Jamie Griffin
DownloadShow Abstract
 Measuring fluctuation in families’ economic conditions is the raison d’être of household panel studies. Accordingly, a particularly challenging critique is that extreme fluctuation in measured economic characteristics might indicate compounding measurement error rather than actual changes in families’ economic wellbeing. In this article, we address this claim by moving beyond the assumption that particularly large fluctuation in economic conditions might be too large to be realistic. Instead, we examine predictors of large fluctuation, capturing sources related to actual socio-economic changes as well as potential sources of measurement error. Using the Panel Study of Income Dynamics, we study between-wave changes in a dimension of economic wellbeing that is especially hard to measure, namely, net worth as an indicator of total family wealth. Our results demonstrate that even very large between-wave changes in net worth can be attributed to actual socio-economic and demographic processes. We do, however, also identify a potential source of measurement error that contributes to large wealth fluctuation, namely, the treatment of incomplete information, presenting a pervasive challenge for any longitudinal survey that includes questions on economic assets. Our results point to ways for improving wealth variables both in the data collection process (e.g., by measuring active savings) and in data processing (e.g., by improving imputation algorithms).
Measuring fluctuation in families’ economic conditions is the raison d’être of household panel studies. Accordingly, a particularly challenging critique is that extreme fluctuation in measured economic characteristics might indicate compounding measurement error rather than actual changes in families’ economic wellbeing. In this article, we address this claim by moving beyond the assumption that particularly large fluctuation in economic conditions might be too large to be realistic. Instead, we examine predictors of large fluctuation, capturing sources related to actual socio-economic changes as well as potential sources of measurement error. Using the Panel Study of Income Dynamics, we study between-wave changes in a dimension of economic wellbeing that is especially hard to measure, namely, net worth as an indicator of total family wealth. Our results demonstrate that even very large between-wave changes in net worth can be attributed to actual socio-economic and demographic processes. We do, however, also identify a potential source of measurement error that contributes to large wealth fluctuation, namely, the treatment of incomplete information, presenting a pervasive challenge for any longitudinal survey that includes questions on economic assets. Our results point to ways for improving wealth variables both in the data collection process (e.g., by measuring active savings) and in data processing (e.g., by improving imputation algorithms). Hide Abstract
- Measuring Wealth and Wealth Inequality
Journal of Economic and Social Measurement (2016), with Robert Schoeni, Arthur Kennickell, and Patricia Andreski
DownloadShow Abstract
 Household wealth and its distribution are topics of broad public debate and increasing scholarly interest. We compare the relative strength of two of the main data sources used in research on the wealth holdings of U.S. households, the Survey of Consumer Finances (SCF) and the Panel Study of Income Dynamics (PSID), by providing a description and explanation of differences in the level and distribution of wealth captured in these two surveys. We identify the factors that account for differences in average net worth but also show that estimates of net worth are similar throughout most of the distribution. Median net worth in the SCF is 6% higher than in the PSID and the largest differences between the two surveys are concentrated in the 1–2 percent wealthiest households, leading to a different view of wealth concentration at the very top but similar results for wealth inequality across most of the distribution.
Household wealth and its distribution are topics of broad public debate and increasing scholarly interest. We compare the relative strength of two of the main data sources used in research on the wealth holdings of U.S. households, the Survey of Consumer Finances (SCF) and the Panel Study of Income Dynamics (PSID), by providing a description and explanation of differences in the level and distribution of wealth captured in these two surveys. We identify the factors that account for differences in average net worth but also show that estimates of net worth are similar throughout most of the distribution. Median net worth in the SCF is 6% higher than in the PSID and the largest differences between the two surveys are concentrated in the 1–2 percent wealthiest households, leading to a different view of wealth concentration at the very top but similar results for wealth inequality across most of the distribution. Hide Abstract
- Neuroscience meets Population Science. What is a representative brain?
Proceedings of the National Academy of Sciences (2013), with Emily Falk, Luke Hyde, Colter Mitchell, et al.
DownloadShow Abstract
 The last decades of neuroscience research have produced immense progress in the methods available to understand brain structure and function. Social, cognitive, clinical, affective, economic, communication, and developmental neurosciences have begun to map the relationships between neuro-psychological processes and behavioral outcomes, yielding a new understanding of human behavior and promising interventions. However, a limitation of this fast moving research is that most findings are based on small samples of convenience. Furthermore, our understanding of individual differences may be distorted by unrepresentative samples, undermining findings regarding brain–behavior mechanisms. These limitations are issues that social demographers, epidemiologists, and other population scientists have tackled, with solutions that can be applied to neuroscience. By contrast, nearly all social science disciplines, including social demography, sociology, political science, economics, communication science, and psychology, make assumptions about processes that involve the brain, but have incorporated neural measures to differing, and often limited, degrees; many still treat the brain as a black box. In this article, we describe and promote a perspective—population neuroscience—that leverages interdisciplinary expertise to (i) emphasize the importance of sampling to more clearly define the relevant populations and sampling strategies needed when using neuroscience methods to address such questions; and (ii) deepen understanding of mechanisms within population science by providing insight regarding underlying neural mechanisms. Doing so will increase our confidence in the generalizability of the findings. We provide examples to illustrate the population neuroscience approach for specific types of research questions and discuss the potential for theoretical and applied advances from this approach across areas.
The last decades of neuroscience research have produced immense progress in the methods available to understand brain structure and function. Social, cognitive, clinical, affective, economic, communication, and developmental neurosciences have begun to map the relationships between neuro-psychological processes and behavioral outcomes, yielding a new understanding of human behavior and promising interventions. However, a limitation of this fast moving research is that most findings are based on small samples of convenience. Furthermore, our understanding of individual differences may be distorted by unrepresentative samples, undermining findings regarding brain–behavior mechanisms. These limitations are issues that social demographers, epidemiologists, and other population scientists have tackled, with solutions that can be applied to neuroscience. By contrast, nearly all social science disciplines, including social demography, sociology, political science, economics, communication science, and psychology, make assumptions about processes that involve the brain, but have incorporated neural measures to differing, and often limited, degrees; many still treat the brain as a black box. In this article, we describe and promote a perspective—population neuroscience—that leverages interdisciplinary expertise to (i) emphasize the importance of sampling to more clearly define the relevant populations and sampling strategies needed when using neuroscience methods to address such questions; and (ii) deepen understanding of mechanisms within population science by providing insight regarding underlying neural mechanisms. Doing so will increase our confidence in the generalizability of the findings. We provide examples to illustrate the population neuroscience approach for specific types of research questions and discuss the potential for theoretical and applied advances from this approach across areas. Hide Abstract
- Future Research in the Social, Behavioral, and Economic Sciences with the PSID
National Science Foundation White Paper (2010), with Charles Brown et al.
DownloadShow Abstract
There are extraordinary opportunities to address the next generation of research challenges in the social, behavioral, and economic sciences that build on the Panel Study of Income Dynamics (PSID). First, PSID offers untapped opportunities to examine questions of relevance to our understanding of environmental sustainability. Second, cross-national harmonization of PSID with other national panel surveys will be instrumental for developing and facilitating new research on the effects of policies and institutions. Third, measuring genetic information in PSID will open a wide range of new studies on social and economic behavior and outcomes. Advances in these areas will provide a foundation for future research and for new interdisciplinary collaborations. Hide Abstract